A few months ago I was discussing with @kaze about the truncation plague on Firefox OS, and he came out with a sentence that left me doubtful:
according to the desktop metrics I had, French is the least compact locale and Chinese is the most compact one
So I had to check it somehow 😉 (in Italy they would call me Saint Thomas for being skeptical).
The basic idea was simple: use Silme to analyze all locales available in Mozilla l10n repositories, comparing string lengths between English and another language.
Here’s the resulting Python script (beware my slowly improving programming skills) and a table with the results (data can be sorted by clicking on column headers).
Sample and Reference
I’m using mozilla-beta as a reference, and comparing each locale against en-GB. Why not en-US? The reason is simple: en-US strings are scattered across the entire mozilla-central repository, so I should do tricks like Transvision in order to create a pseudo en-US string-only repository. Using en-GB leads to less precise results (see below), but for the sake of this analysis I considered it an acceptable compromise.
I’m not checking all folders, only the main ones (‘browser’, ‘dom’, ‘mail’, ‘mobile’, ‘netwerk’, ‘security’, ‘services’, ‘suite’, ‘toolkit’, ‘webapprt’). This still generates an archive of almost 18,000 strings for locales translating all products, so it seems a decent sample.
Caveats and Weird Results
String 1: en-GB 2 characters, locale X 4 characters -> +2 characters, +100%
String 2: en-GB 8 characters, locale X 4 characters -> -4 characters, -50%
Average for locale X: -1 characters, +25% (sum of differences divided by total number of items).
Not sure if this is the best choice, but I couldn’t think of an alternative. Note also that I’m ignoring single character strings (access keys, shortcuts).
In the table you’ll see a global column (average results) and “buckets”, with string groups based on en-GB original length. Too bad these groups are often unreliable because of the “concatenation conundrum”, where one string could be created by concatenating 3 different labels.
Typical example to create a sentence with a link (note that concatenation should be always avoided):
sentence.before = Hey, this is a sentence.link = very interesting link sentence.after = .
In Italian this could be localized as
sentence.before = Ehi, questo sentence.link = link sentence.after = è veramente interessante.
Do you see what just happened here? Length comparison based on groups just became less interesting, both averages and maximum/minimum differences.
Anyhow, here’s a good image (graph based on global difference in percentage) that I’d like to call “Why using English as a reference for designing UI may not be a great idea”.
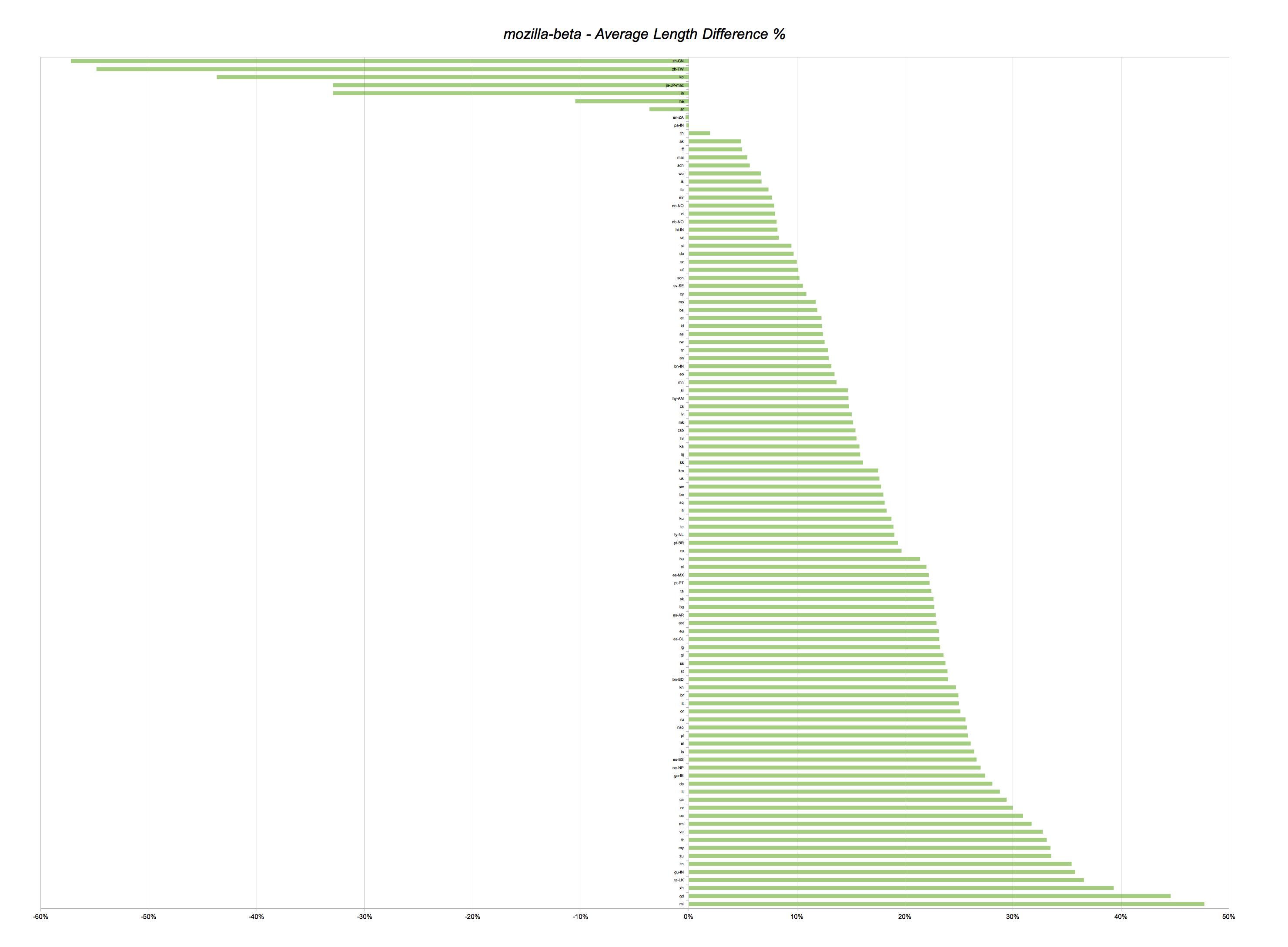
Open link in a new tab/window to see the full image
Why not use Gaia directly?
This sounds like a good idea: we have a real en-US repository, and we don’t have concatenations. But there are some disadvantages as well:
- Most locales already did at least two rounds of QA, so a lot of strings have already been (heavily) shortened to fit in the UI. So data could be less useful and interesting.
- Several locales are incomplete on gaia-l10n. For this very reason I excluded all locales with less than 1000 strings translated.
Here’s the same table for Gaia. And, again, a similar graph based on global difference in percentage.
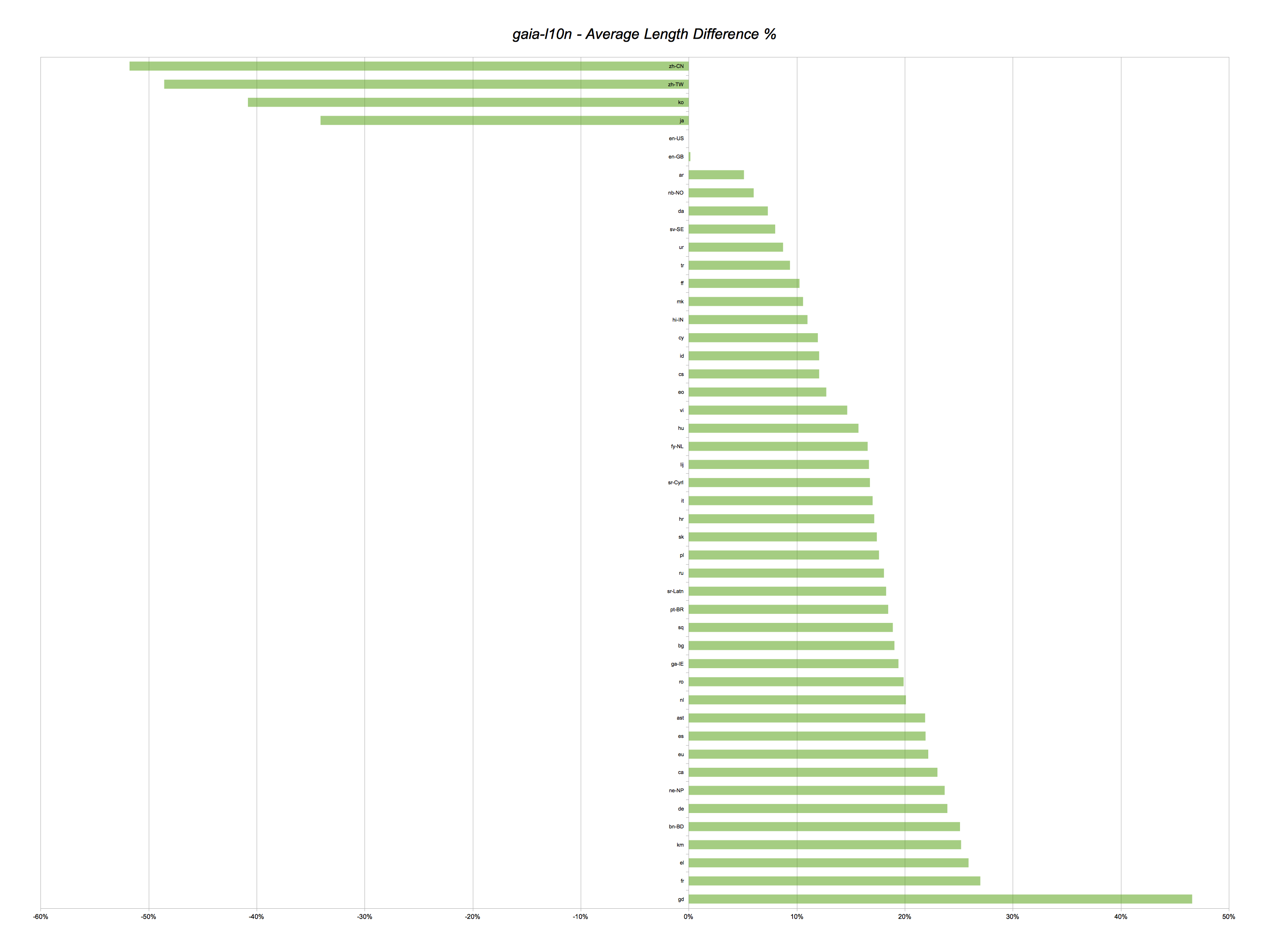 Open link in a new tab/window to see the full image
Open link in a new tab/window to see the full image
Fun facts:
- We know that en-GB is 0.16% longer than en-US, at least on Gaia.
- A simple word as “OK” (2 characters) can become as long as “Kulungile” (9) in Xhosa, or “Ceart ma-thà” (12) in Scottish Gaelic.
Leave a Reply